Computer Vision For Avoiding Accidents
by: Suksham, Suyash, Tushar, Snehal and Rudreshwar
Road accidents are one of the major problems the world has been troubled with since the dawn of Automobiles. For the year 2010, The World Health Organization (WHO) estimated that 1.25 million deaths were related to road traffic injuries. India alone had recorded 1,54,732 motor vehicle crash-related deaths, averaging around 423 people per day, in 2019. In Europe, the statistics also indicate that each minute, there are 50 road deaths recorded in the year 2017. As it is sad to hear, India records highest number of road accidents around the world.
As the population increased over the years, the utilization of vehicles has increased proportionally. This expansion has resulted in steady increase of the street mishaps. Congestion of vehicles on road, a driver under alcohol or drug influence, distracted driving, street racing, faulty design of cars or traffic lights, tailgating, improper turns, and driving in the wrong direction are some of the genuine causes of accidents across the globe. Even with the advancements in security system in vehicles, street level frameworks, we do not see reduction in road accidents. The reason being these systems are designed from the point of Humans and we are prone to do errors. With the development in Machine learning and computer vision field, time has come to utilize this resource to solve major issues of the world, which includes Road Accidents.
Object Detection Model for vehicles:
Now lets try to understand the architecture of object detection model for accident avoiding systems:

Proposed architecture consists of the following 3 main parts as, input video feed, training database, vehicle and event detection and finally alerting the users. The following are some modules of systems.
1. Positive Object Image Creation:
This process consists of viewing each of the images containing the positives, which are the images containing the objects of interest. It is done in two steps:
a) Selection of positive and negative images: Very first step of the proposed project is to selection of positive and negative images. This process is to be done manually. First, one must collect plenty of images to train the database. Positive images are the images which contain the object of interest i.e. vehicles and negative images are images without the desired object i.e. empty roads.

b) Clipping the positive images: Clipping process takes the positive images and on manually selection of desired objects, it selects the objects, clips it from full image and records its coordinates in that image. This coordinate selection data consists of information as number of objects present, size of that object and coordinates of the object. This process also leads to a question that how many images are enough to get a HAAR process done. And the answer is, bigger the database, robust the system. But a ratio is maintained for convenience, ratio like 1000 positives: 2000 negatives is a good ratio.
2. Training database:
It is the most important process of the complete model. Real world performance of the system is depends on it. After cleaning and labeling of data set properly, Computer vision model is trained on it. This can take up to 20 hours. This process takes all negative, positive images and respective description files as input. Process them and at the end it produces training .xml file, which is used for detection process which is training the database.
3. Detection Process:
In this step, recursively for each Signal generated from the previous step, detection program checks the conditions. Each time a condition violated, a signal to event detection process will be generated. Again, we can split it into two process:
a) Event detection: This task does the real-time action of detecting desired objects from live feed or the video. This uses trained database and compare live data. Compare video frame by frame with samples, detects vehicles on matching, highlight detected objects, count detected objects/vehicles, and compare with road capacity. Implement traffic event detection ideas like illegal moment in restricted area, exceeding maximum capacity etc. And at the end, alert users on any events of illegal movements.

In the next picture, detected objects are marked with rectangles. This process is repeated for each frame and each vehicle detected. As there are two vehicles on the current frame, both detected and marked with rectangles. The moment of vehicles in the restricted area is detected and marked with red rectangles. This process triggers the alerting system to check for that whether any traffic event is occurred.

b) Generating Alert: Next step is to alert the users. For each frame of the video sequence, number of vehicles on the screen are displayed on alert screen, and an alert message depending on the traffic condition is displayed. On detection of vehicles at restricted area, alert screen displays warning messages.
Gaze Tracking:
Gaze estimation is a process to estimate and track the 3D line of sight of a person, or simply, where a person is looking. The device or apparatus used to track gaze by analyzing eye movements is called a gaze tracker. A gaze tracker performs two main tasks simultaneously: localization of the eye position in the video or images, and tracking its motion to determine the gaze direction. The eye-gaze tracking system consists of one CCD camera and two mirrors. Based on geometric and linear algebra calculations, the mirrors rotate to follow head movements to keep the eyes within the view of the camera. It also consists of a hierarchical generalized regression neural networks (H-GRNN) scheme to map eye and mirror parameters to gaze

Now we will be looking into the three algorithms used for feature detection which consists of The Longest Line Scanning (LLS), Occluded Circular Edge Matching (OCEM), and Blink detection.
Real World Example:
Tesla headed and co-founded by Elon Musk is the world leader in self-driving vehicles. Around the world, till date only 167 accidents have occurred while using Tesla’s Autopilot, company’s famed self-driving system. In the beginning of July 2020, Tesla claimed to have achieved Level 5 autonomy i.e., fully self-driving vehicle. Tesla’s tasks are well-known today. From lane detection, pedestrian tracking, they must cover everything and anticipate every scenario. For that, they use 8 cameras fused with RADARs, which give detailed video feed from every aspect for most effective obstacle detection.To process all that data in real time they have designed their own special neural network architecture called HydraNets. HydraNets have backbones trained on all objects, and heads trained on specific tasks. This improves the inference speed as well as the training speed.
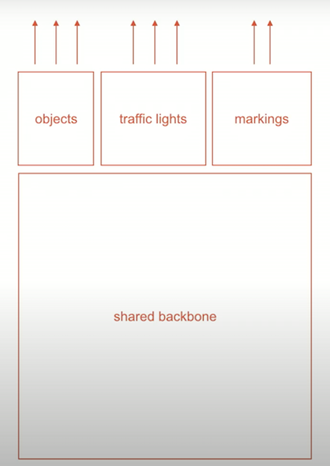
Now we will see those active safety features using computer vision which makes Tesla’s vehicles less prone to accidents:
1) Automatic Emergency Braking
As the name suggests, this feature applies braking in situations, where the obstacle comes in front of the car suddenly and the driver does not have enough time to react.
2) Front and Side Collision Warning
With so many cameras to cover the sides of the car, Tesla is able to keep an eye out for obstacles on the sides of the car to warn the driver of anything spontaneous that might result in a collision. The beeping sounds warn the driver and appropriate action can be taken either by the car or by the driver.
3) Obstacle Aware Acceleration and Emergency Lane Departure Avoidance
With this feature, the car is automatically able to reduce acceleration if it detects something in front of your car and steers away from that obstacle to avoid a collision. Also, when changing lanes, a car is detected in the other lane, the car will automatically steer you back to your lane avoiding any potential encounter with the traffic. Blind Spot Monitoring features help take care of such scenarios to look where the driver cannot.
Conclusion:
We can use technologies we have developed over time to reduce the accidents. With our advancements in computer vision and sensory technologies, we can make modern traffic management processes more efficient. Autonomous vehicles equipped with modern sensors and computer vision system which can communicate with each other in interconnected system are the future.This will reduced the number of accidents significantly. With our advanced image recognition technology, tools in place to disrupt the automotive industry and make it safer for the world of tomorrow. Our synthetic datasets could be applied to traffic flow to manage it more efficiently, as well. Computer vision technologies have the potential to revolutionize our daily lives, making everyday doings like driving and transportation easier and safer for all involved.
